

Hacía mucho que no escribía un artículo y ya iba teniendo ganas :)
Han pasado 6 meses de pandemia, eventos online, retransmisiones por Twich y muchas novedades del mundo Alexa.
Quiero profundizar en algunos temas de APL y voy a usar mi skill de Estrenos de Cine para ello. En este post vamos a ver concretamente cómo añadir un Pager a nuestra skill con APL y cómo añadirle navegación por voz.
¿Cómo ha evolucionado visualmente la skill Estrenos de Cine con APL?
En antiguos post ya conté el paso de la skill de tener salida solo para voz a tener salida para dispositivos con pantalla. He de reconocer que lo que hice en su momento fue muy simple, me faltaban muchos conocimientos y algún que otro copy&paste de skills de ejemplo acabaron en la mía.
Es posible que cuando estéis leyendo este post esa versión ya no esté en producción y esté la que voy a contar ahora (o una incluso posterior). Por eso os pongo por aquí un gif de cómo era esa versión inicial de la skill con APL:

Y con lo que voy a contar en este post, le he dado un lavado de cara que pinta así:

Además del cambio visual quise añadirle navegación por voz, simplemente por probarlo y jugar con eso.
Añadiendo APL Pager
Desde que metí APL a la skill siempre quise añadir el póster a la respuesta por pantalla. En realidad a nivel de arquitectura de información no ha cambiado nada aparte de llegar la imagen. Los otros dos campos por cada película son los mismos de antes: título y fecha de estreno.
Hay un par de soluciones provistas por APL para hacer "un tipo de carrusel":
- Sequences > te darían algo como lo que tenía en la versión inicial: un carrusel por el cual puedes hacer scroll. A ese carrusel le podría haber añadido la imagen y haberlo usado perfectamente. Así a la vez normalmente tendrías más de un elemento visible.
- Pager > es un carrusel pero a pantalla completa. Es decir, tienes un elemento de carrusel en cada momento. Mi intención era crear una experiencia de "showroom" y por eso opté por esta opción.
La idea de esta primera evolución visual es darle un lavado de cara aprovechando las pantallas con el detalle de la imagen.
Antes de entrar en detalle técnico del Pager quería decir que la imagen usa el componente AlexaImage en vez de APL Image. El primero sería como una versión vitaminada del segundo con temas como responsive entre otros. Veréis el código y por eso no merece la pena explicar mucho más de esta parte.
Eso si, no seáis como yo. Leed bien la documentación porque la URL tiene que cumplir ciertos requisitos y me tiré un tiempo para descubrir por qué a mi no me hacía render en el Echo Show pero sí en el simulador :D
Documento APL
Yo ya usaba un componente Sequence para el listado vertical de estrenos. Lo que hice fue reestructurar un poco el layout para meter el Pager ocupando todo el ancho y la parte de alto restante de la cabecera y el footer (del footer os hablo luego).
El resto, los params de entrada y tal, es todo igual que lo que había ya antes. Es casi cambiar un componente por el otro. Fijaos en que tiene un "id" definido. Esto lo usaremos luego para la navegación por voz.
En el back no hay cambios que hacer para empezar a usar este componente. Si el dispositivo que tienes es táctil o tienes mando, podrás pasar de página sin hacer nada más.
Añadiendo navegación por voz
A modo experimento quería añadir la capacidad de navegación por voz a la skill. Con navegación me refiero en este caso a pasar de página diciendo a Alexa: "Alexa, siguiente estreno", "Alexa, siguiente", etc
Aunque para este caso de uso puede no resultar muy interesante, sí que creo que puede haber otros casos de uso (en la cocina por ejemplo) donde tengas alguna skill con Pager y se pudiera implementar esto así.
Para el experimento implementé la capacidad de "navegar hacía el siguiente elemento" pero no "navegar hacía el anterior" aunque aplica lo mismo que voy a contar y sería bastante simple. Comentar relacionado con esto que el Pager tiene distintas configuraciones para la navegación:
normal– Por defecto. Te puedes mover libremente hacía adelante o atrás.none– El usuario no puede cambiar de página. En este caso se usa un comando,AutoPage, para moverlo de forma programática.wrap– Aun no he conseguido ver la diferencia entre este modo y el modo normal :Dforward-only- Solo te puedes mover hacia delante.
A nivel del documento APL no hay que añadir nada para tener navegación por voz, todo el peso aquí recae en el modelo de interacción y el back.
Interaction Model
Para reconocer la acción vocal de avanzar en la paginación tenemos que crear un nuevo intent y meterle los utterances correspondientes:
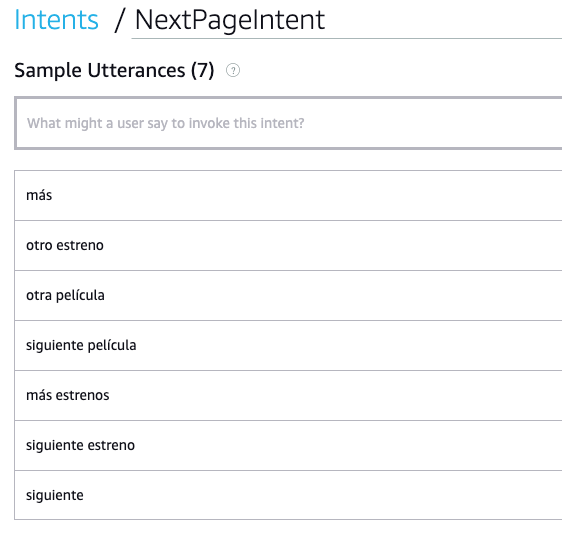
Backend
Ahora la parte más interesante de esto. Desde el back tenemos que hacer varias cosas para que todo funcione. Pero, antes de eso, voy a contar un concepto nuevo que vamos a usar: APL Commands.
Los APL Commands nos permiten cambiar la presentación, visual en este caso, de la skill en el dispositivo. Os pongo el link a la documentación oficial y me voy a centrar en los dos que nos interesan hoy:
AutoPage: este comando permite configurar la transición automática de cada elemento del Pager. Permite configurar el delay de comienzo y cada cuánto tiempo cambia de elemento.SetPage: este comando permite cambiar el elemento representado en el Pager indicando o un valor relativo (desde donde estás se mueve N posiciones) o un valor absoluto (se mueve al índice que se le indique).
En mi caso, al querer hacer navegación por voz, con una transición hacía delante de los estrenos, opté por usar el comando de SetPage de forma relativa. Esto lo podemos ver en el código del handle para nuestro nuevo NextPageIntent:
- En el método
handlees donde está toda la magia y creamos una respuesta que ejecutará el comando deSetPage. Al comando le vamos a decir que usaremos posición relativa y que el valor a mover será1. Con ese valor podemos jugar para distintos efectos como saltarnos elementos (con un2nos saltamos uno por ejemplo), ir hacía detrás (con un número negativo), etc. - Necesitamos indicarle el id del componente Pager sobre el cual queremos ejecutar el comando. Este id será el mismo que le hayamos puesto en el documento APL.
- Por último, indicar un token es obligatorio. Este token es el mismo con el que se hace el comando de
RenderDocumentDirectivedel documento en pantalla. De esta forma queda relacionado el documento donde está el componente sobre el que tiene que aplicar el comando. Yo no hacía uso de ese token por lo que tuve que añadirlo en los dos handlers donde se crea el documento con los estrenos.withToken("newReleasesSkillAPLToken")
El Footer
Al tener ahora más interacción disponible para el usuario en modo vocal, es recomendable hacer uso de un footer en la skill para dar pistas o sugerencias de interacciones.
Para ello añadí un footer al documento APL con, de momento, una cadena estática que dice "siguiente estreno", para que el usuario tenga una pista de que puede navegar de esa forma.
Para ello he usado el componente AlexaFooter pero lo oculto si el dispositivo Alexa es redondo (el Echo Spot) porque no se ve bien ahí.
Para añadir la "wake word" que cada usuario tenga en su dispositivo le tenemos que añadir una función en el template de datos que ya nos creará la frase hint final.
Y con eso tendríamos la skill funcionando con el Pager y la navegación por voz. Es verdad que en este caso igual no es tan útil pero quería hacer el experimento y ver la complejidad. En una segunda evolución quiero añadir un segundo nivel de detalle para cada película donde tener información concreta como duración, puntuación, sinopsis, etc. Quizás haya información que no sea visual, si la sinopsis es grande igual es mejor que esa parte la dé por voz, y así combinar ambas experiencias. Ya veré qué hago cuando llegue a ese punto ;)